NOTE: Apart from
 (and even then it's questionable, I'm Scottish). These are machine translated in languages I don't read. If they're terrible please contact me.
(and even then it's questionable, I'm Scottish). These are machine translated in languages I don't read. If they're terrible please contact me.
You can see how this translation was done in this article.













Friday, 02 August 2024
//11 minute read
Markdown is een lichtgewicht mark-up taal die u kunt gebruiken om opmaakelementen toe te voegen aan tekstdocumenten in platte tekst. Gemaakt door John Gruber in 2004, Markdown is nu een van de meest populaire markup talen ter wereld.
Op deze site gebruik ik een super eenvoudige benadering van bloggen, hebben geprobeerd en mislukt om een blog in het verleden te onderhouden Ik wilde het zo eenvoudig mogelijk te maken om te schrijven en te publiceren berichten. Ik gebruik markdown om mijn berichten te schrijven en deze site heeft een enkele dienst met behulp van Markdig om de markdown naar HTML te converteren.
In een woord eenvoud. Dit wordt geen super high traffic site, ik gebruik ASP.NET OutPutCache om de pagina's te cachen en ik ga het niet zo vaak updaten. Ik wilde de site zo eenvoudig mogelijk te houden en geen zorgen te maken over de overhead van een statische site generator zowel in termen van het bouwproces en de complexiteit van de site.
Om te verduidelijken; statische site generatoren zoals Hugo / Jekyll etc...kan een goede oplossing zijn voor veel sites, maar voor deze wilde ik het zo simpel houden voor mij zo goed mogelijk. Ik ben 25 jaar ASP.NET veteraan dus begrijp het van binnen en buiten. Deze site ontwerp voegt complexiteit; Ik heb views, diensten, controllers en een heleboel handmatige HTML & CSS maar ik ben comfortabel met dat.
Ik zet gewoon een nieuw.md bestand in de map Markdown en de site picks het op en rendert het (als ik herinner om het aet als inhoud, dit zorgt ervoor dat het beschikbaar is in de uitvoerbestanden!)
Dan wanneer ik checkin de site naar GitHub de actie loopt en de site wordt bijgewerkt. Simpel!
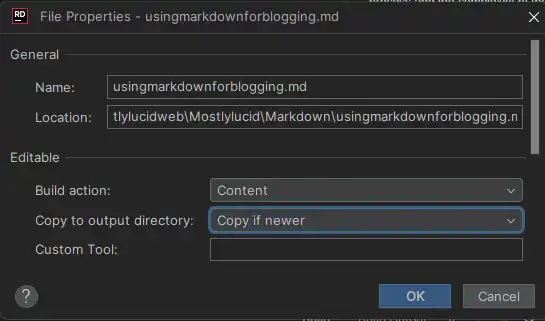
Aangezien ik net het beeld hier heb toegevoegd, zal ik je laten zien hoe ik het deed. Ik heb gewoon de afbeelding toegevoegd aan de map wwwroot/articleimages en ernaar verwezen in het markdown bestand zoals dit:

Ik voeg dan een uitbreiding toe aan mijn Markdig pipeline die deze herschrijft naar de juiste URL (alles over eenvoud). Zie hier voor de broncode voor de extensie.
using Markdig;
using Markdig.Renderers;
using Markdig.Syntax;
using Markdig.Syntax.Inlines;
namespace Mostlylucid.MarkDigExtensions;
public class ImgExtension : IMarkdownExtension
{
public void Setup(MarkdownPipelineBuilder pipeline)
{
pipeline.DocumentProcessed += ChangeImgPath;
}
public void Setup(MarkdownPipeline pipeline, IMarkdownRenderer renderer)
{
}
public void ChangeImgPath(MarkdownDocument document)
{
foreach (var link in document.Descendants<LinkInline>())
if (link.IsImage)
link.Url = "/articleimages/" + link.Url;
}
}
De BlogService is een eenvoudige dienst die de markdown bestanden van de Markdown map leest en ze converteert naar HTML met behulp van Markdig.
De volledige bron hiervoor is hieronder en Hier..
using System.Globalization; using System.Text.RegularExpressions; using Markdig; using Microsoft.Extensions.Caching.Memory; using Mostlylucid.MarkDigExtensions; using Mostlylucid.Models.Blog;
namespace Mostlylucid.Services;
public class BlogService { private const string Path = "Markdown"; private const string CacheKey = "Categories";
private static readonly Regex DateRegex = new(
@"<datetime class=""hidden"">(\d{4}-\d{2}-\d{2}T\d{2}:\d{2})</datetime>",
RegexOptions.Compiled | RegexOptions.IgnoreCase | RegexOptions.NonBacktracking);
private static readonly Regex WordCoountRegex = new(@"\b\w+\b",
RegexOptions.Compiled | RegexOptions.Multiline | RegexOptions.IgnoreCase | RegexOptions.NonBacktracking);
private static readonly Regex CategoryRegex = new(@"<!--\s*category\s*--\s*([^,]+?)\s*(?:,\s*([^,]+?)\s*)?-->",
RegexOptions.Compiled | RegexOptions.Singleline);
private readonly ILogger<BlogService> _logger;
private readonly IMemoryCache _memoryCache;
private readonly MarkdownPipeline pipeline;
public BlogService(IMemoryCache memoryCache, ILogger<BlogService> logger)
{
_logger = logger;
_memoryCache = memoryCache;
pipeline = new MarkdownPipelineBuilder().UseAdvancedExtensions().Use<ImgExtension>().Build();
ListCategories();
}
private Dictionary<string, List<string>> GetFromCache()
{
return _memoryCache.Get<Dictionary<string, List<string>>>(CacheKey) ?? new Dictionary<string, List<string>>();
}
private void SetCache(Dictionary<string, List<string>> categories)
{
_memoryCache.Set(CacheKey, categories, new MemoryCacheEntryOptions
{
AbsoluteExpirationRelativeToNow = TimeSpan.FromHours(12)
});
}
private void ListCategories()
{
var cacheCats = GetFromCache();
var pages = Directory.GetFiles("Markdown", "*.md");
var count = 0;
foreach (var page in pages)
{
var pageAlreadyAdded = cacheCats.Values.Any(x => x.Contains(page));
if (pageAlreadyAdded) continue;
var text = File.ReadAllText(page);
var categories = GetCategories(text);
if (!categories.Any()) continue;
count++;
foreach (var category in categories)
if (cacheCats.TryGetValue(category, out var pagesList))
{
pagesList.Add(page);
cacheCats[category] = pagesList;
_logger.LogInformation("Added category {Category} for {Page}", category, page);
}
else
{
cacheCats.Add(category, new List<string> { page });
_logger.LogInformation("Created category {Category} for {Page}", category, page);
}
}
if (count > 0) SetCache(cacheCats);
}
public List<string> GetCategories()
{
var cacheCats = GetFromCache();
return cacheCats.Keys.ToList();
}
public List<PostListModel> GetPostsByCategory(string category)
{
var pages = GetFromCache()[category];
return GetPosts(pages.ToArray());
}
public BlogPostViewModel? GetPost(string postName)
{
try
{
var path = System.IO.Path.Combine(Path, postName + ".md");
var page = GetPage(path, true);
return new BlogPostViewModel
{
Categories = page.categories, WordCount = WordCount(page.restOfTheLines), Content = page.processed,
PublishedDate = page.publishDate, Slug = page.slug, Title = page.title
};
}
catch (Exception e)
{
_logger.LogError(e, "Error getting post {PostName}", postName);
return null;
}
}
private int WordCount(string text)
{
return WordCoountRegex.Matches(text).Count;
}
private string GetSlug(string fileName)
{
var slug = System.IO.Path.GetFileNameWithoutExtension(fileName);
return slug.ToLowerInvariant();
}
private static string[] GetCategories(string markdownText)
{
var matches = CategoryRegex.Matches(markdownText);
var categories = matches
.SelectMany(match => match.Groups.Cast<Group>()
.Skip(1) // Skip the entire match group
.Where(group => group.Success) // Ensure the group matched
.Select(group => group.Value.Trim()))
.ToArray();
return categories;
}
public (string title, string slug, DateTime publishDate, string processed, string[] categories, string
restOfTheLines) GetPage(string page, bool html)
{
var fileInfo = new FileInfo(page);
// Ensure the file exists
if (!fileInfo.Exists) throw new FileNotFoundException("The specified file does not exist.", page);
// Read all lines from the file
var lines = File.ReadAllLines(page);
// Get the title from the first line
var title = lines.Length > 0 ? Markdown.ToPlainText(lines[0].Trim()) : string.Empty;
// Concatenate the rest of the lines with newline characters
var restOfTheLines = string.Join(Environment.NewLine, lines.Skip(1));
// Extract categories from the text
var categories = GetCategories(restOfTheLines);
var publishedDate = fileInfo.CreationTime;
var publishDate = DateRegex.Match(restOfTheLines).Groups[1].Value;
if (!string.IsNullOrWhiteSpace(publishDate))
publishedDate = DateTime.ParseExact(publishDate, "yyyy-MM-ddTHH:mm", CultureInfo.InvariantCulture);
// Remove category tags from the text
restOfTheLines = CategoryRegex.Replace(restOfTheLines, "");
restOfTheLines = DateRegex.Replace(restOfTheLines, "");
// Process the rest of the lines as either HTML or plain text
var processed =
html ? Markdown.ToHtml(restOfTheLines, pipeline) : Markdown.ToPlainText(restOfTheLines, pipeline);
// Generate the slug from the page filename
var slug = GetSlug(page);
// Return the parsed and processed content
return (title, slug, publishedDate, processed, categories, restOfTheLines);
}
public List<PostListModel> GetPosts(string[] pages)
{
List<PostListModel> pageModels = new();
foreach (var page in pages)
{
var pageInfo = GetPage(page, false);
var summary = Markdown.ToPlainText(pageInfo.restOfTheLines).Substring(0, 100) + "...";
pageModels.Add(new PostListModel
{
Categories = pageInfo.categories, Title = pageInfo.title,
Slug = pageInfo.slug, WordCount = WordCount(pageInfo.restOfTheLines),
PublishedDate = pageInfo.publishDate, Summary = summary
});
}
pageModels = pageModels.OrderByDescending(x => x.PublishedDate).ToList();
return pageModels;
}
public List<PostListModel> GetPostsForFiles()
{
var pages = Directory.GetFiles("Markdown", "*.md");
return GetPosts(pages);
}
}
</details>
Zoals je kunt zien heeft dit een paar elementen:
### Bestanden verwerken
De code om de markdown-bestanden naar HTML te verwerken is vrij eenvoudig, ik gebruik de Markdig-bibliotheek om de markdown naar HTML te converteren en dan gebruik ik een paar reguliere expressies om de categorieën en de gepubliceerde datum uit het markdown-bestand te halen.
De GetPage methode wordt gebruikt om de inhoud van het markdown bestand te extraheren, het heeft een paar stappen:
1. De titel uitpakken
Op afspraak gebruik ik de eerste regel van het markdown bestand als de titel van het bericht. Dus ik kan gewoon doen:
```csharp
var lines = File.ReadAllLines(page);
// Get the title from the first line
var title = lines.Length > 0 ? Markdown.ToPlainText(lines[0].Trim()) : string.Empty;
Omdat de titel is geprefixeerd met "#" gebruik ik de Markdown.ToPlainText methode om de "#" van de titel te verwijderen.
// Concatenate the rest of the lines with newline characters
var restOfTheLines = string.Join(Environment.NewLine, lines.Skip(1));
// Extract categories from the text
var categories = GetCategories(restOfTheLines);
// Remove category tags from the text
restOfTheLines = CategoryRegex.Replace(restOfTheLines, "");
De methode GetCategories gebruikt een reguliere expressie om de categorieën uit het markdown-bestand te halen.
private static readonly Regex CategoryRegex = new(@"<!--\s*category\s*--\s*([^,]+?)\s*(?:,\s*([^,]+?)\s*)?-->",
RegexOptions.Compiled | RegexOptions.Singleline);
private static string[] GetCategories(string markdownText)
{
var matches = CategoryRegex.Matches(markdownText);
var categories = matches
.SelectMany(match => match.Groups.Cast<Group>()
.Skip(1) // Skip the entire match group
.Where(group => group.Success) // Ensure the group matched
.Select(group => group.Value.Trim()))
.ToArray();
return categories;
}
private static readonly Regex DateRegex = new(
@"<datetime class=""hidden"">(\d{4}-\d{2}-\d{2}T\d{2}:\d{2})</datetime>",
RegexOptions.Compiled | RegexOptions.IgnoreCase | RegexOptions.NonBacktracking);
var publishedDate = fileInfo.CreationTime;
var publishDate = DateRegex.Match(restOfTheLines).Groups[1].Value;
if (!string.IsNullOrWhiteSpace(publishDate))
publishedDate = DateTime.ParseExact(publishDate, "yyyy-MM-ddTHH:mm", CultureInfo.InvariantCulture);
restOfTheLines = DateRegex.Replace(restOfTheLines, "");
pipeline = new MarkdownPipelineBuilder().UseAdvancedExtensions().Use<ImgExtension>().Build();
var processed =
html ? Markdown.ToHtml(restOfTheLines, pipeline) : Markdown.ToPlainText(restOfTheLines, pipeline);
Haal de'slug' Dit is gewoon de bestandsnaam zonder de extensie:
private string GetSlug(string fileName)
{
var slug = System.IO.Path.GetFileNameWithoutExtension(fileName);
return slug.ToLowerInvariant();
}
Teruggeven van de inhoud Nu hebben we pagina-inhoud die we kunnen weergeven voor de blog!
// Ensure the file exists
if (!fileInfo.Exists) throw new FileNotFoundException("The specified file does not exist.", page);
// Read all lines from the file
var lines = File.ReadAllLines(page);
// Get the title from the first line
var title = lines.Length > 0 ? Markdown.ToPlainText(lines[0].Trim()) : string.Empty;
// Concatenate the rest of the lines with newline characters
var restOfTheLines = string.Join(Environment.NewLine, lines.Skip(1));
// Extract categories from the text
var categories = GetCategories(restOfTheLines);
var publishedDate = fileInfo.CreationTime;
var publishDate = DateRegex.Match(restOfTheLines).Groups[1].Value;
if (!string.IsNullOrWhiteSpace(publishDate))
publishedDate = DateTime.ParseExact(publishDate, "yyyy-MM-ddTHH:mm", CultureInfo.InvariantCulture);
// Remove category tags from the text
restOfTheLines = CategoryRegex.Replace(restOfTheLines, "");
restOfTheLines = DateRegex.Replace(restOfTheLines, "");
// Process the rest of the lines as either HTML or plain text
var processed =
html ? Markdown.ToHtml(restOfTheLines, pipeline) : Markdown.ToPlainText(restOfTheLines, pipeline);
// Generate the slug from the page filename
var slug = GetSlug(page);
// Return the parsed and processed content
return (title, slug, publishedDate, processed, categories, restOfTheLines);
}
</details>
De code hieronder laat zien hoe ik de lijst van blog berichten genereren, het maakt gebruik van de `GetPage(page, false)` methode om de titel, categorieën, gepubliceerde datum en de verwerkte inhoud te extraheren.
```csharp
public List<PostListModel> GetPosts(string[] pages)
{
List<PostListModel> pageModels = new();
foreach (var page in pages)
{
var pageInfo = GetPage(page, false);
var summary = Markdown.ToPlainText(pageInfo.restOfTheLines).Substring(0, 100) + "...";
pageModels.Add(new PostListModel
{
Categories = pageInfo.categories, Title = pageInfo.title,
Slug = pageInfo.slug, WordCount = WordCount(pageInfo.restOfTheLines),
PublishedDate = pageInfo.publishDate, Summary = summary
});
}
pageModels = pageModels.OrderByDescending(x => x.PublishedDate).ToList();
return pageModels;
}
public List<PostListModel> GetPostsForFiles()
{
var pages = Directory.GetFiles("Markdown", "*.md");
return GetPosts(pages);
}
