NOTE: Apart from
 (and even then it's questionable, I'm Scottish). These are machine translated in languages I don't read. If they're terrible please contact me.
(and even then it's questionable, I'm Scottish). These are machine translated in languages I don't read. If they're terrible please contact me.
You can see how this translation was done in this article.













Friday, 02 August 2024
//10 minute read
العلامة التنازلية هي لغة تعريف خفيفة الوزن يمكنك استخدامها لإضافة عناصر تنسيق إلى وثائق نصية بسيطة. الذي أنشأه جون غروبر في عام 2004، أصبح ماركداون الآن إحدى اللغات الأكثر شعبية في العالم.
في هذا الموقع أستخدم نهجاً بسيطاً جداً للمدونات، بعد أن حاولت وفشلت في الحفاظ على مدونة في الماضي أردت أن أجعل من السهل قدر الإمكان كتابة ونشر المقالات. أستعمل العلامة التنازلية لكتابة مواقعي وهذا الموقع لديه خدمة واحدة تستخدم & إلى تحويل إلى HTML.
[رابعاً -
في كلمة بسيطة. هذا لن يكون موقع مرور عالي جداً، أنا أستخدم ASP.net. outputcache لإخفاء الصفحات ولن أقوم بتحديثها في كثير من الأحيان. أردت أن أبقي الموقع بسيطاً قدر الإمكان وليس من الضروري أن أقلق بشأن ما فوق مولد الموقع الساكن من حيث عملية البناء وتعقيد الموقع على حد سواء.
توضيح؛ مولدات المواقع الساكنة مثل: أولاً / يُقَرن يمكن أن يكون حلاً جيداً للعديد من المواقع لكن لهذا أردت أن أبقيه بسيطاً من أجلي وقد يكون ذلك ممكناً. أنا في الـ25 من عمري مُحاربة مُحاربة مُحاربة مُحاربة مُحاربة مُحاربة مُحاربة مُحاربة مُحاربة مُحاربة، لذا ففهمها من الداخل والخارج. تصميم هذا الموقع يزيد من التعقيد، لدي وجهات نظر، خدمات، متحكمات و الكثير من الصور اليدوية HTML و CSS لكنني مرتاح لذلك.
ببساطة أُسقط ملف جديد في مجلد العلامة السفلية والموقع يلتقطه ويُعيده (عندما أتذكر أن أضعه كمحتوي، هذا يضمن أنه قابل للإبراز في ملفات المخرجات!)
ثم عندما أتحقق من الموقع إلى جيت هوب يجري العمل ويتم تحديث الموقع. مبسّط! مبسّط!
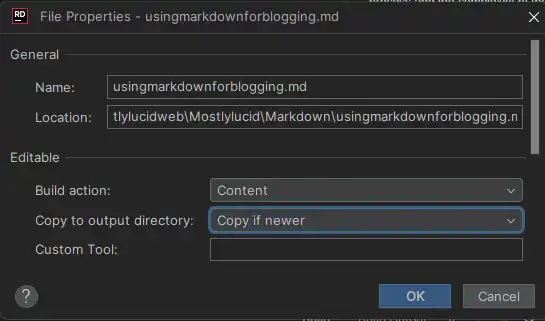
بما أنني أضفت للتو الصورة هنا، سأريكم كيف فعلتها. ببساطة أضفت الصورة إلى مجلد wwwroot/ articleimages و أشرت إليها في ملف العلامة السفلية مثل هذا:

ثم اضف امتدادا الى خط هاتفي الذي يعيد كتابة هذه الى العنوان الصحيح (كل شيء عن البساطة). انظر هنا لرمز المصدر للتمديد.
using Markdig;
using Markdig.Renderers;
using Markdig.Syntax;
using Markdig.Syntax.Inlines;
namespace Mostlylucid.MarkDigExtensions;
public class ImgExtension : IMarkdownExtension
{
public void Setup(MarkdownPipelineBuilder pipeline)
{
pipeline.DocumentProcessed += ChangeImgPath;
}
public void Setup(MarkdownPipeline pipeline, IMarkdownRenderer renderer)
{
}
public void ChangeImgPath(MarkdownDocument document)
{
foreach (var link in document.Descendants<LinkInline>())
if (link.IsImage)
link.Url = "/articleimages/" + link.Url;
}
}
الـ BlogService هو a بسيط خدمة قراءة ملفات من معلمة أسفل مجلد و حوّلهم إلى HTML استخدام.
وفيما يلي المصدر الكامل لهذا المصدر: هنا هنا.
using System.Globalization; using System.Text.RegularExpressions; using Markdig; using Microsoft.Extensions.Caching.Memory; using Mostlylucid.MarkDigExtensions; using Mostlylucid.Models.Blog;
namespace Mostlylucid.Services;
public class BlogService { private const string Path = "Markdown"; private const string CacheKey = "Categories";
private static readonly Regex DateRegex = new(
@"<datetime class=""hidden"">(\d{4}-\d{2}-\d{2}T\d{2}:\d{2})</datetime>",
RegexOptions.Compiled | RegexOptions.IgnoreCase | RegexOptions.NonBacktracking);
private static readonly Regex WordCoountRegex = new(@"\b\w+\b",
RegexOptions.Compiled | RegexOptions.Multiline | RegexOptions.IgnoreCase | RegexOptions.NonBacktracking);
private static readonly Regex CategoryRegex = new(@"<!--\s*category\s*--\s*([^,]+?)\s*(?:,\s*([^,]+?)\s*)?-->",
RegexOptions.Compiled | RegexOptions.Singleline);
private readonly ILogger<BlogService> _logger;
private readonly IMemoryCache _memoryCache;
private readonly MarkdownPipeline pipeline;
public BlogService(IMemoryCache memoryCache, ILogger<BlogService> logger)
{
_logger = logger;
_memoryCache = memoryCache;
pipeline = new MarkdownPipelineBuilder().UseAdvancedExtensions().Use<ImgExtension>().Build();
ListCategories();
}
private Dictionary<string, List<string>> GetFromCache()
{
return _memoryCache.Get<Dictionary<string, List<string>>>(CacheKey) ?? new Dictionary<string, List<string>>();
}
private void SetCache(Dictionary<string, List<string>> categories)
{
_memoryCache.Set(CacheKey, categories, new MemoryCacheEntryOptions
{
AbsoluteExpirationRelativeToNow = TimeSpan.FromHours(12)
});
}
private void ListCategories()
{
var cacheCats = GetFromCache();
var pages = Directory.GetFiles("Markdown", "*.md");
var count = 0;
foreach (var page in pages)
{
var pageAlreadyAdded = cacheCats.Values.Any(x => x.Contains(page));
if (pageAlreadyAdded) continue;
var text = File.ReadAllText(page);
var categories = GetCategories(text);
if (!categories.Any()) continue;
count++;
foreach (var category in categories)
if (cacheCats.TryGetValue(category, out var pagesList))
{
pagesList.Add(page);
cacheCats[category] = pagesList;
_logger.LogInformation("Added category {Category} for {Page}", category, page);
}
else
{
cacheCats.Add(category, new List<string> { page });
_logger.LogInformation("Created category {Category} for {Page}", category, page);
}
}
if (count > 0) SetCache(cacheCats);
}
public List<string> GetCategories()
{
var cacheCats = GetFromCache();
return cacheCats.Keys.ToList();
}
public List<PostListModel> GetPostsByCategory(string category)
{
var pages = GetFromCache()[category];
return GetPosts(pages.ToArray());
}
public BlogPostViewModel? GetPost(string postName)
{
try
{
var path = System.IO.Path.Combine(Path, postName + ".md");
var page = GetPage(path, true);
return new BlogPostViewModel
{
Categories = page.categories, WordCount = WordCount(page.restOfTheLines), Content = page.processed,
PublishedDate = page.publishDate, Slug = page.slug, Title = page.title
};
}
catch (Exception e)
{
_logger.LogError(e, "Error getting post {PostName}", postName);
return null;
}
}
private int WordCount(string text)
{
return WordCoountRegex.Matches(text).Count;
}
private string GetSlug(string fileName)
{
var slug = System.IO.Path.GetFileNameWithoutExtension(fileName);
return slug.ToLowerInvariant();
}
private static string[] GetCategories(string markdownText)
{
var matches = CategoryRegex.Matches(markdownText);
var categories = matches
.SelectMany(match => match.Groups.Cast<Group>()
.Skip(1) // Skip the entire match group
.Where(group => group.Success) // Ensure the group matched
.Select(group => group.Value.Trim()))
.ToArray();
return categories;
}
public (string title, string slug, DateTime publishDate, string processed, string[] categories, string
restOfTheLines) GetPage(string page, bool html)
{
var fileInfo = new FileInfo(page);
// Ensure the file exists
if (!fileInfo.Exists) throw new FileNotFoundException("The specified file does not exist.", page);
// Read all lines from the file
var lines = File.ReadAllLines(page);
// Get the title from the first line
var title = lines.Length > 0 ? Markdown.ToPlainText(lines[0].Trim()) : string.Empty;
// Concatenate the rest of the lines with newline characters
var restOfTheLines = string.Join(Environment.NewLine, lines.Skip(1));
// Extract categories from the text
var categories = GetCategories(restOfTheLines);
var publishedDate = fileInfo.CreationTime;
var publishDate = DateRegex.Match(restOfTheLines).Groups[1].Value;
if (!string.IsNullOrWhiteSpace(publishDate))
publishedDate = DateTime.ParseExact(publishDate, "yyyy-MM-ddTHH:mm", CultureInfo.InvariantCulture);
// Remove category tags from the text
restOfTheLines = CategoryRegex.Replace(restOfTheLines, "");
restOfTheLines = DateRegex.Replace(restOfTheLines, "");
// Process the rest of the lines as either HTML or plain text
var processed =
html ? Markdown.ToHtml(restOfTheLines, pipeline) : Markdown.ToPlainText(restOfTheLines, pipeline);
// Generate the slug from the page filename
var slug = GetSlug(page);
// Return the parsed and processed content
return (title, slug, publishedDate, processed, categories, restOfTheLines);
}
public List<PostListModel> GetPosts(string[] pages)
{
List<PostListModel> pageModels = new();
foreach (var page in pages)
{
var pageInfo = GetPage(page, false);
var summary = Markdown.ToPlainText(pageInfo.restOfTheLines).Substring(0, 100) + "...";
pageModels.Add(new PostListModel
{
Categories = pageInfo.categories, Title = pageInfo.title,
Slug = pageInfo.slug, WordCount = WordCount(pageInfo.restOfTheLines),
PublishedDate = pageInfo.publishDate, Summary = summary
});
}
pageModels = pageModels.OrderByDescending(x => x.PublishedDate).ToList();
return pageModels;
}
public List<PostListModel> GetPostsForFiles()
{
var pages = Directory.GetFiles("Markdown", "*.md");
return GetPosts(pages);
}
}
</details>
كما ترون هذا يحتوي على عناصر قليلة:
### ملفات التجهيز
الـ رمز إلى معالجة أسفل ملفات إلى HTML هو بسيط جدا، أنا استخدام مكتبة إلى تحويل علامة أسفل إلى HTML ثم أنا استخدام بعض التعابير العادية لاستخلاص الفئات والتاريخ المنشور من ملفّ.
تستخدم طريقة GetPage لانتزاع محتوى ملف العلامة التنازلية، ولها بضع خطوات:
1. مقتطفات اللعنوان
بواسطة الاتفاقية أستخدم السطر الأول من الملف كعنوان للوظيفة لذا يمكنني ببساطة القيام بما يلي:
```csharp
var lines = File.ReadAllLines(page);
// Get the title from the first line
var title = lines.Length > 0 ? Markdown.ToPlainText(lines[0].Trim()) : string.Empty;
كما أن العنوان مُبَدَأ بـ "#" أنا أستخدم طريقة علامة down. tou PlainText لإزالة "#" من العنوان.
// Concatenate the rest of the lines with newline characters
var restOfTheLines = string.Join(Environment.NewLine, lines.Skip(1));
// Extract categories from the text
var categories = GetCategories(restOfTheLines);
// Remove category tags from the text
restOfTheLines = CategoryRegex.Replace(restOfTheLines, "");
تستخدم طريقة getCategores تعبير عادي لاستخلاص الفئات من ملف العلامة التنازلية.
private static readonly Regex CategoryRegex = new(@"<!--\s*category\s*--\s*([^,]+?)\s*(?:,\s*([^,]+?)\s*)?-->",
RegexOptions.Compiled | RegexOptions.Singleline);
private static string[] GetCategories(string markdownText)
{
var matches = CategoryRegex.Matches(markdownText);
var categories = matches
.SelectMany(match => match.Groups.Cast<Group>()
.Skip(1) // Skip the entire match group
.Where(group => group.Success) // Ensure the group matched
.Select(group => group.Value.Trim()))
.ToArray();
return categories;
}
private static readonly Regex DateRegex = new(
@"<datetime class=""hidden"">(\d{4}-\d{2}-\d{2}T\d{2}:\d{2})</datetime>",
RegexOptions.Compiled | RegexOptions.IgnoreCase | RegexOptions.NonBacktracking);
var publishedDate = fileInfo.CreationTime;
var publishDate = DateRegex.Match(restOfTheLines).Groups[1].Value;
if (!string.IsNullOrWhiteSpace(publishDate))
publishedDate = DateTime.ParseExact(publishDate, "yyyy-MM-ddTHH:mm", CultureInfo.InvariantCulture);
restOfTheLines = DateRegex.Replace(restOfTheLines, "");
pipeline = new MarkdownPipelineBuilder().UseAdvancedExtensions().Use<ImgExtension>().Build();
var processed =
html ? Markdown.ToHtml(restOfTheLines, pipeline) : Markdown.ToPlainText(restOfTheLines, pipeline);
احصل على 'المُسَلِّج' هذا هو ببساطة اسم الملف بدون إمتداد:
private string GetSlug(string fileName)
{
var slug = System.IO.Path.GetFileNameWithoutExtension(fileName);
return slug.ToLowerInvariant();
}
الآن لدينا محتوى صفحة يمكننا عرضها للمدونة!
// Ensure the file exists
if (!fileInfo.Exists) throw new FileNotFoundException("The specified file does not exist.", page);
// Read all lines from the file
var lines = File.ReadAllLines(page);
// Get the title from the first line
var title = lines.Length > 0 ? Markdown.ToPlainText(lines[0].Trim()) : string.Empty;
// Concatenate the rest of the lines with newline characters
var restOfTheLines = string.Join(Environment.NewLine, lines.Skip(1));
// Extract categories from the text
var categories = GetCategories(restOfTheLines);
var publishedDate = fileInfo.CreationTime;
var publishDate = DateRegex.Match(restOfTheLines).Groups[1].Value;
if (!string.IsNullOrWhiteSpace(publishDate))
publishedDate = DateTime.ParseExact(publishDate, "yyyy-MM-ddTHH:mm", CultureInfo.InvariantCulture);
// Remove category tags from the text
restOfTheLines = CategoryRegex.Replace(restOfTheLines, "");
restOfTheLines = DateRegex.Replace(restOfTheLines, "");
// Process the rest of the lines as either HTML or plain text
var processed =
html ? Markdown.ToHtml(restOfTheLines, pipeline) : Markdown.ToPlainText(restOfTheLines, pipeline);
// Generate the slug from the page filename
var slug = GetSlug(page);
// Return the parsed and processed content
return (title, slug, publishedDate, processed, categories, restOfTheLines);
}
</details>
الشفرة الواردة أدناه تظهر كيف أقوم بتوليد قائمة المدونين `GetPage(page, false)` لاستخلاص العنوان والفئات والتاريخ المنشور والمحتوى المجهز.
```csharp
public List<PostListModel> GetPosts(string[] pages)
{
List<PostListModel> pageModels = new();
foreach (var page in pages)
{
var pageInfo = GetPage(page, false);
var summary = Markdown.ToPlainText(pageInfo.restOfTheLines).Substring(0, 100) + "...";
pageModels.Add(new PostListModel
{
Categories = pageInfo.categories, Title = pageInfo.title,
Slug = pageInfo.slug, WordCount = WordCount(pageInfo.restOfTheLines),
PublishedDate = pageInfo.publishDate, Summary = summary
});
}
pageModels = pageModels.OrderByDescending(x => x.PublishedDate).ToList();
return pageModels;
}
public List<PostListModel> GetPostsForFiles()
{
var pages = Directory.GetFiles("Markdown", "*.md");
return GetPosts(pages);
}
