This is a viewer only at the moment see the article on how this works.
To update the preview hit Ctrl-Alt-R (or ⌘-Alt-R on Mac) or Enter to refresh. The Save icon lets you save the markdown file to disk
This is a preview from the server running through my markdig pipeline
खंडित एक छोटी सी मार्कअप भाषा है जिसे आप सादा पाठ दस्तावेज़ में फ़ॉर्मेटिंग जोड़ने के लिए उपयोग कर सकते हैं. सन् 2004 में जॉन गिगर द्वारा बनाया गया, मार्क नीचे अब दुनिया की सबसे लोकप्रिय मार्कअप भाषाओं में से एक है ।
इस साइट पर मैं ब्लॉगिंग के लिए एक सुपर सरल तरीका इस्तेमाल करता हूँ, पिछले में एक ब्लॉग को बनाए रखने में असफल रहा......मैं इसे आसान बनाना चाहता था के रूप में लिखना और पोस्ट प्रकाशित करना चाहता था. मैं अपने पोस्ट लिखने के लिए चिह्न का उपयोग करें तथा इस साइट में एक एकल सेवा है सिगिग चिह्न नीचे को एचटीएमएल में परिवर्तित करने के लिए.
[विषय
एक शब्द में सरल. यह एक सुपर ऊँची यातायात स्थल होने के लिए नहीं जा रहा है, मैं एन. मैं इस साइट को उतना सरल रखना चाहता था जितना कि संभव हो ।
स्पष्ट करने के लिए; स्थिर साइट जेनरेटर जैसे हूगोworld. kgm / जेकील ... कई साइटों के लिए एक अच्छा समाधान हो सकता है लेकिन इस एक के लिए मैं इसे सरल के रूप में रखना चाहता था मेरे लिए संभव के रूप में. मैं 25 साल का हूँ. WEEEENT अनुभवी तो अंदर और बाहर समझ में आता है. इस साइट डिजाइन में जटिल रचना होती है; मुझे लगता है कि सेवाओं, सेवाओं, नियंत्रण, और मैनुअल एचटीएमएल एवं सीएसएस के एक mution है लेकिन मैं उस के साथ आराम से कर रहा हूँ.
मैं सिर्फ एक नया.md फ़ाइल को चिह्नित फ़ोल्डर में छोड़ देता है और साइट इसे चुन लेता है (जब मैं इसे सामग्री के रूप में याद करता हूँ तो यह निश्चित करता हूँ कि यह आउटपुट फ़ाइलों में एक जावाीय है!)
फिर जब मैं GallHHHHHW के लिए साइट की जाँच करता हूँ...... और साइट अद्यतन किया जाता है. बहुत बढ़िया!
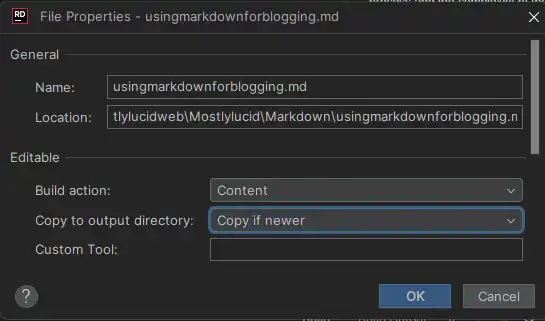
क्योंकि मैं सिर्फ यहाँ छवि जोड़ा है, मैं आपको दिखाता हूँ कि कैसे मैंने यह किया. मैंने छवि को wwwroth/arizs में केवल जोड़ा और इस तरह की फ़ाइल में इसका उपयोग किया:

फिर मैं अपने मार्कडिस्क में एक एक्सटेंशन जोड़ता हूँ जो इन्हें सही यूआरएल में फिर से लिख देता है (सभी सरलता के बारे में). एक्सटेंशन के लिए स्रोत कोड के लिए यहाँ देखें.
using Markdig;
using Markdig.Renderers;
using Markdig.Syntax;
using Markdig.Syntax.Inlines;
namespace Mostlylucid.MarkDigExtensions;
public class ImgExtension : IMarkdownExtension
{
public void Setup(MarkdownPipelineBuilder pipeline)
{
pipeline.DocumentProcessed += ChangeImgPath;
}
public void Setup(MarkdownPipeline pipeline, IMarkdownRenderer renderer)
{
}
public void ChangeImgPath(MarkdownDocument document)
{
foreach (var link in document.Descendants<LinkInline>())
if (link.IsImage)
link.Url = "/articleimages/" + link.Url;
}
}
ब्लॉगेज एक सरल सेवा है जो मार्क नीचे दिए गए फ़ोल्डर से चिह्न नीचे की फ़ाइलों को पढ़ता है तथा उन्हें एचटीएमएल में परिवर्तित करता है.
इस के लिए पूरा स्रोत नीचे है और यहाँ.
using System.Globalization; using System.Text.RegularExpressions; using Markdig; using Microsoft.Extensions.Caching.Memory; using Mostlylucid.MarkDigExtensions; using Mostlylucid.Models.Blog;
namespace Mostlylucid.Services;
public class BlogService { private const string Path = "Markdown"; private const string CacheKey = "Categories";
private static readonly Regex DateRegex = new(
@"<datetime class=""hidden"">(\d{4}-\d{2}-\d{2}T\d{2}:\d{2})</datetime>",
RegexOptions.Compiled | RegexOptions.IgnoreCase | RegexOptions.NonBacktracking);
private static readonly Regex WordCoountRegex = new(@"\b\w+\b",
RegexOptions.Compiled | RegexOptions.Multiline | RegexOptions.IgnoreCase | RegexOptions.NonBacktracking);
private static readonly Regex CategoryRegex = new(@"<!--\s*category\s*--\s*([^,]+?)\s*(?:,\s*([^,]+?)\s*)?-->",
RegexOptions.Compiled | RegexOptions.Singleline);
private readonly ILogger<BlogService> _logger;
private readonly IMemoryCache _memoryCache;
private readonly MarkdownPipeline pipeline;
public BlogService(IMemoryCache memoryCache, ILogger<BlogService> logger)
{
_logger = logger;
_memoryCache = memoryCache;
pipeline = new MarkdownPipelineBuilder().UseAdvancedExtensions().Use<ImgExtension>().Build();
ListCategories();
}
private Dictionary<string, List<string>> GetFromCache()
{
return _memoryCache.Get<Dictionary<string, List<string>>>(CacheKey) ?? new Dictionary<string, List<string>>();
}
private void SetCache(Dictionary<string, List<string>> categories)
{
_memoryCache.Set(CacheKey, categories, new MemoryCacheEntryOptions
{
AbsoluteExpirationRelativeToNow = TimeSpan.FromHours(12)
});
}
private void ListCategories()
{
var cacheCats = GetFromCache();
var pages = Directory.GetFiles("Markdown", "*.md");
var count = 0;
foreach (var page in pages)
{
var pageAlreadyAdded = cacheCats.Values.Any(x => x.Contains(page));
if (pageAlreadyAdded) continue;
var text = File.ReadAllText(page);
var categories = GetCategories(text);
if (!categories.Any()) continue;
count++;
foreach (var category in categories)
if (cacheCats.TryGetValue(category, out var pagesList))
{
pagesList.Add(page);
cacheCats[category] = pagesList;
_logger.LogInformation("Added category {Category} for {Page}", category, page);
}
else
{
cacheCats.Add(category, new List<string> { page });
_logger.LogInformation("Created category {Category} for {Page}", category, page);
}
}
if (count > 0) SetCache(cacheCats);
}
public List<string> GetCategories()
{
var cacheCats = GetFromCache();
return cacheCats.Keys.ToList();
}
public List<PostListModel> GetPostsByCategory(string category)
{
var pages = GetFromCache()[category];
return GetPosts(pages.ToArray());
}
public BlogPostViewModel? GetPost(string postName)
{
try
{
var path = System.IO.Path.Combine(Path, postName + ".md");
var page = GetPage(path, true);
return new BlogPostViewModel
{
Categories = page.categories, WordCount = WordCount(page.restOfTheLines), Content = page.processed,
PublishedDate = page.publishDate, Slug = page.slug, Title = page.title
};
}
catch (Exception e)
{
_logger.LogError(e, "Error getting post {PostName}", postName);
return null;
}
}
private int WordCount(string text)
{
return WordCoountRegex.Matches(text).Count;
}
private string GetSlug(string fileName)
{
var slug = System.IO.Path.GetFileNameWithoutExtension(fileName);
return slug.ToLowerInvariant();
}
private static string[] GetCategories(string markdownText)
{
var matches = CategoryRegex.Matches(markdownText);
var categories = matches
.SelectMany(match => match.Groups.Cast<Group>()
.Skip(1) // Skip the entire match group
.Where(group => group.Success) // Ensure the group matched
.Select(group => group.Value.Trim()))
.ToArray();
return categories;
}
public (string title, string slug, DateTime publishDate, string processed, string[] categories, string
restOfTheLines) GetPage(string page, bool html)
{
var fileInfo = new FileInfo(page);
// Ensure the file exists
if (!fileInfo.Exists) throw new FileNotFoundException("The specified file does not exist.", page);
// Read all lines from the file
var lines = File.ReadAllLines(page);
// Get the title from the first line
var title = lines.Length > 0 ? Markdown.ToPlainText(lines[0].Trim()) : string.Empty;
// Concatenate the rest of the lines with newline characters
var restOfTheLines = string.Join(Environment.NewLine, lines.Skip(1));
// Extract categories from the text
var categories = GetCategories(restOfTheLines);
var publishedDate = fileInfo.CreationTime;
var publishDate = DateRegex.Match(restOfTheLines).Groups[1].Value;
if (!string.IsNullOrWhiteSpace(publishDate))
publishedDate = DateTime.ParseExact(publishDate, "yyyy-MM-ddTHH:mm", CultureInfo.InvariantCulture);
// Remove category tags from the text
restOfTheLines = CategoryRegex.Replace(restOfTheLines, "");
restOfTheLines = DateRegex.Replace(restOfTheLines, "");
// Process the rest of the lines as either HTML or plain text
var processed =
html ? Markdown.ToHtml(restOfTheLines, pipeline) : Markdown.ToPlainText(restOfTheLines, pipeline);
// Generate the slug from the page filename
var slug = GetSlug(page);
// Return the parsed and processed content
return (title, slug, publishedDate, processed, categories, restOfTheLines);
}
public List<PostListModel> GetPosts(string[] pages)
{
List<PostListModel> pageModels = new();
foreach (var page in pages)
{
var pageInfo = GetPage(page, false);
var summary = Markdown.ToPlainText(pageInfo.restOfTheLines).Substring(0, 100) + "...";
pageModels.Add(new PostListModel
{
Categories = pageInfo.categories, Title = pageInfo.title,
Slug = pageInfo.slug, WordCount = WordCount(pageInfo.restOfTheLines),
PublishedDate = pageInfo.publishDate, Summary = summary
});
}
pageModels = pageModels.OrderByDescending(x => x.PublishedDate).ToList();
return pageModels;
}
public List<PostListModel> GetPostsForFiles()
{
var pages = Directory.GetFiles("Markdown", "*.md");
return GetPosts(pages);
}
}
</details>
जैसा कि आप देख सकते हैं यह कुछ तत्वों में है:
### प्रक्रिया फ़ाइल
कोड जो फ़ाइलें HTML में खड़ी हैं वह बहुत ही सरल है, मैं मार्किडी लाइब्रेरी का उपयोग करता हूँ जो चिह्न नीचे को एचटीएमएल में परिवर्तित करने के लिए करता हूँ और फिर मैं कुछ नियमित एक्सप्रेशन का उपयोग करता हूँ वर्ग और तारीख़ चिह्न फ़ाइल से प्रकाशित.
प्राप्त पृष्ठ विधि चिह्न फ़ाइल की सामग्री निकालने के लिए प्रयोग में आता है, इसमें कुछ चरण हैं:
1. शीर्षक निकालें
अधिवेशन के द्वारा मैं पोस्ट का शीर्षक के रूप में चिह्न के प्रथम पंक्ति का प्रयोग करता हूँ । तो मैं बस कर सकते हैं:
```csharp
var lines = File.ReadAllLines(page);
// Get the title from the first line
var title = lines.Length > 0 ? Markdown.ToPlainText(lines[0].Trim()) : string.Empty;
शीर्षक के रूप में कार्य के साथ उपसर्ग किया गया है "मैं मरकुस नीचे का प्रयोग करता हूँ. किसी विशेष पाठ विधि को शीर्षक से हटाने के लिए.
// Concatenate the rest of the lines with newline characters
var restOfTheLines = string.Join(Environment.NewLine, lines.Skip(1));
// Extract categories from the text
var categories = GetCategories(restOfTheLines);
// Remove category tags from the text
restOfTheLines = CategoryRegex.Replace(restOfTheLines, "");
ढूंढने का तरीका एक रेगुलर एक्सप्रेशन का प्रयोग करता है जो कि चिह्न नीचे फ़ाइल से वर्गों को निकालने के लिए करता है.
private static readonly Regex CategoryRegex = new(@"<!--\s*category\s*--\s*([^,]+?)\s*(?:,\s*([^,]+?)\s*)?-->",
RegexOptions.Compiled | RegexOptions.Singleline);
private static string[] GetCategories(string markdownText)
{
var matches = CategoryRegex.Matches(markdownText);
var categories = matches
.SelectMany(match => match.Groups.Cast<Group>()
.Skip(1) // Skip the entire match group
.Where(group => group.Success) // Ensure the group matched
.Select(group => group.Value.Trim()))
.ToArray();
return categories;
}
private static readonly Regex DateRegex = new(
@"<datetime class=""hidden"">(\d{4}-\d{2}-\d{2}T\d{2}:\d{2})</datetime>",
RegexOptions.Compiled | RegexOptions.IgnoreCase | RegexOptions.NonBacktracking);
var publishedDate = fileInfo.CreationTime;
var publishDate = DateRegex.Match(restOfTheLines).Groups[1].Value;
if (!string.IsNullOrWhiteSpace(publishDate))
publishedDate = DateTime.ParseExact(publishDate, "yyyy-MM-ddTHH:mm", CultureInfo.InvariantCulture);
restOfTheLines = DateRegex.Replace(restOfTheLines, "");
pipeline = new MarkdownPipelineBuilder().UseAdvancedExtensions().Use<ImgExtension>().Build();
var processed =
html ? Markdown.ToHtml(restOfTheLines, pipeline) : Markdown.ToPlainText(restOfTheLines, pipeline);
'lulug' प्राप्त करें यह सिर्फ एक्सटेंशन के बगैर फ़ाइलनाम है:
private string GetSlug(string fileName)
{
var slug = System.IO.Path.GetFileNameWithoutExtension(fileName);
return slug.ToLowerInvariant();
}
विषयवस्तु वापस लें अब हमारे पास पृष्ठ सामग्री है हम ब्लॉग के लिए प्रदर्शन कर सकते हैं!
// Ensure the file exists
if (!fileInfo.Exists) throw new FileNotFoundException("The specified file does not exist.", page);
// Read all lines from the file
var lines = File.ReadAllLines(page);
// Get the title from the first line
var title = lines.Length > 0 ? Markdown.ToPlainText(lines[0].Trim()) : string.Empty;
// Concatenate the rest of the lines with newline characters
var restOfTheLines = string.Join(Environment.NewLine, lines.Skip(1));
// Extract categories from the text
var categories = GetCategories(restOfTheLines);
var publishedDate = fileInfo.CreationTime;
var publishDate = DateRegex.Match(restOfTheLines).Groups[1].Value;
if (!string.IsNullOrWhiteSpace(publishDate))
publishedDate = DateTime.ParseExact(publishDate, "yyyy-MM-ddTHH:mm", CultureInfo.InvariantCulture);
// Remove category tags from the text
restOfTheLines = CategoryRegex.Replace(restOfTheLines, "");
restOfTheLines = DateRegex.Replace(restOfTheLines, "");
// Process the rest of the lines as either HTML or plain text
var processed =
html ? Markdown.ToHtml(restOfTheLines, pipeline) : Markdown.ToPlainText(restOfTheLines, pipeline);
// Generate the slug from the page filename
var slug = GetSlug(page);
// Return the parsed and processed content
return (title, slug, publishedDate, processed, categories, restOfTheLines);
}
</details>
नीचे दिया गया कोड दिखाता है कि मैं ब्लॉग पोस्ट की सूची कैसे तैयार करता हूँ यह प्रयोग करता है `GetPage(page, false)` शीर्षक, श्रेणी, प्रकाशित तारीख़ तथा प्रोसेस सामग्री निकालने का विधि.
```csharp
public List<PostListModel> GetPosts(string[] pages)
{
List<PostListModel> pageModels = new();
foreach (var page in pages)
{
var pageInfo = GetPage(page, false);
var summary = Markdown.ToPlainText(pageInfo.restOfTheLines).Substring(0, 100) + "...";
pageModels.Add(new PostListModel
{
Categories = pageInfo.categories, Title = pageInfo.title,
Slug = pageInfo.slug, WordCount = WordCount(pageInfo.restOfTheLines),
PublishedDate = pageInfo.publishDate, Summary = summary
});
}
pageModels = pageModels.OrderByDescending(x => x.PublishedDate).ToList();
return pageModels;
}
public List<PostListModel> GetPostsForFiles()
{
var pages = Directory.GetFiles("Markdown", "*.md");
return GetPosts(pages);
}
