This is a viewer only at the moment see the article on how this works.
To update the preview hit Ctrl-Alt-R (or ⌘-Alt-R on Mac) or Enter to refresh. The Save icon lets you save the markdown file to disk
This is a preview from the server running through my markdig pipeline
Markdown είναι μια ελαφριά γλώσσα μαρκαδόρου που μπορείτε να χρησιμοποιήσετε για να προσθέσετε στοιχεία μορφοποίησης σε έγγραφα κειμένου απλού κειμένου. Δημιουργήθηκε από John Gruber το 2004, Markdown είναι τώρα μια από τις πιο δημοφιλείς γλώσσες μαρκαδόρου.
Σε αυτό το site χρησιμοποιώ μια πολύ απλή προσέγγιση στο blogging, έχοντας προσπαθήσει και απέτυχε να διατηρήσει ένα blog στο παρελθόν ήθελα να είναι όσο το δυνατόν πιο εύκολο να γράψετε και να δημοσιεύσετε δημοσιεύσεις. Χρησιμοποιώ το markdown για να γράψω τις δημοσιεύσεις μου και αυτό το site έχει μια ενιαία υπηρεσία χρησιμοποιώντας ΜάρκτιγκCity name (optional, probably does not need a translation) να μετατρέψει το markdown σε HTML.
Με μια λέξη απλότητα. Αυτό δεν πρόκειται να είναι ένα σούπερ υψηλής κυκλοφορίας τοποθεσία, χρησιμοποιώ ASP.NET OutPutCache για να κρύψει τις σελίδες και δεν πρόκειται να το ενημερώσετε τόσο συχνά. Ήθελα να κρατήσω το site όσο το δυνατόν πιο απλό και δεν χρειάζεται να ανησυχείτε για το πάνω μέρος μιας στατικής γεννήτριας τοποθεσίας τόσο από την άποψη της διαδικασίας κατασκευής και την πολυπλοκότητα του site.
Για να διευκρινίσετε. Στατικές γεννήτριες τοποθεσίας όπως ΧιούγκοCity name (optional, probably does not need a translation) / ΤζέκιλCity name (optional, probably does not need a translation) κ.λπ..μπορεί να είναι μια καλή λύση για πολλές ιστοσελίδες, αλλά για αυτό ήθελα να το κρατήσω τόσο απλό για μένα όσο το δυνατόν περισσότερο. Είμαι 25 χρόνια βετεράνος του ASP.NET, οπότε κατάλαβέ το μέσα και έξω. Αυτός ο σχεδιασμός ιστοσελίδας προσθέτει πολυπλοκότητα; Έχω απόψεις, υπηρεσίες, ελεγκτές και ένα LOT του εγχειριδίου HTML & CSS, αλλά είμαι άνετα με αυτό.
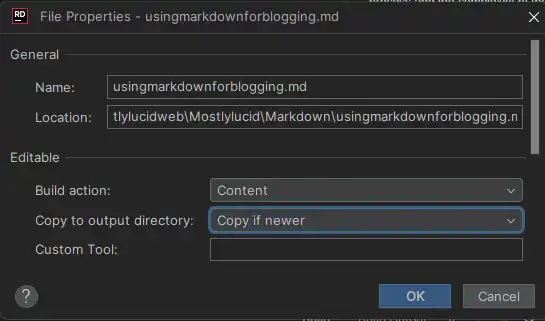
Απλά ρίχνω ένα νέο αρχείο.md στο φάκελο Markdown και ο ιστότοπος το παίρνει και το κάνει (όταν θυμάμαι να το aet ως περιεχόμενο, αυτό εξασφαλίζει ότι είναι avaiable στα αρχεία εξόδου!)
Στη συνέχεια, όταν ελέγχω το site για να GitHub η δράση τρέχει και η ιστοσελίδα ενημερώνεται. Απλό!
Αφού πρόσθεσα την εικόνα εδώ, θα σου δείξω πώς το έκανα. Απλά πρόσθεσα την εικόνα στο φάκελο wwwroot/articleimages και την ανέφερα στο αρχείο markdown όπως αυτό:

Στη συνέχεια, προσθέτω μια επέκταση στον αγωγό Markdig μου που ξαναγράφει αυτά στη σωστή URL (όλα σχετικά με την απλότητα). Δείτε εδώ για τον πηγαίο κώδικα για την επέκταση.
using Markdig;
using Markdig.Renderers;
using Markdig.Syntax;
using Markdig.Syntax.Inlines;
namespace Mostlylucid.MarkDigExtensions;
public class ImgExtension : IMarkdownExtension
{
public void Setup(MarkdownPipelineBuilder pipeline)
{
pipeline.DocumentProcessed += ChangeImgPath;
}
public void Setup(MarkdownPipeline pipeline, IMarkdownRenderer renderer)
{
}
public void ChangeImgPath(MarkdownDocument document)
{
foreach (var link in document.Descendants<LinkInline>())
if (link.IsImage)
link.Url = "/articleimages/" + link.Url;
}
}
Το BlogService είναι μια απλή υπηρεσία που διαβάζει τα αρχεία markdown από το φάκελο Markdown και τα μετατρέπει σε HTML χρησιμοποιώντας Markdig.
Η πλήρης πηγή γι' αυτό είναι κάτω και Ορίστε..
using System.Globalization; using System.Text.RegularExpressions; using Markdig; using Microsoft.Extensions.Caching.Memory; using Mostlylucid.MarkDigExtensions; using Mostlylucid.Models.Blog;
namespace Mostlylucid.Services;
public class BlogService { private const string Path = "Markdown"; private const string CacheKey = "Categories";
private static readonly Regex DateRegex = new(
@"<datetime class=""hidden"">(\d{4}-\d{2}-\d{2}T\d{2}:\d{2})</datetime>",
RegexOptions.Compiled | RegexOptions.IgnoreCase | RegexOptions.NonBacktracking);
private static readonly Regex WordCoountRegex = new(@"\b\w+\b",
RegexOptions.Compiled | RegexOptions.Multiline | RegexOptions.IgnoreCase | RegexOptions.NonBacktracking);
private static readonly Regex CategoryRegex = new(@"<!--\s*category\s*--\s*([^,]+?)\s*(?:,\s*([^,]+?)\s*)?-->",
RegexOptions.Compiled | RegexOptions.Singleline);
private readonly ILogger<BlogService> _logger;
private readonly IMemoryCache _memoryCache;
private readonly MarkdownPipeline pipeline;
public BlogService(IMemoryCache memoryCache, ILogger<BlogService> logger)
{
_logger = logger;
_memoryCache = memoryCache;
pipeline = new MarkdownPipelineBuilder().UseAdvancedExtensions().Use<ImgExtension>().Build();
ListCategories();
}
private Dictionary<string, List<string>> GetFromCache()
{
return _memoryCache.Get<Dictionary<string, List<string>>>(CacheKey) ?? new Dictionary<string, List<string>>();
}
private void SetCache(Dictionary<string, List<string>> categories)
{
_memoryCache.Set(CacheKey, categories, new MemoryCacheEntryOptions
{
AbsoluteExpirationRelativeToNow = TimeSpan.FromHours(12)
});
}
private void ListCategories()
{
var cacheCats = GetFromCache();
var pages = Directory.GetFiles("Markdown", "*.md");
var count = 0;
foreach (var page in pages)
{
var pageAlreadyAdded = cacheCats.Values.Any(x => x.Contains(page));
if (pageAlreadyAdded) continue;
var text = File.ReadAllText(page);
var categories = GetCategories(text);
if (!categories.Any()) continue;
count++;
foreach (var category in categories)
if (cacheCats.TryGetValue(category, out var pagesList))
{
pagesList.Add(page);
cacheCats[category] = pagesList;
_logger.LogInformation("Added category {Category} for {Page}", category, page);
}
else
{
cacheCats.Add(category, new List<string> { page });
_logger.LogInformation("Created category {Category} for {Page}", category, page);
}
}
if (count > 0) SetCache(cacheCats);
}
public List<string> GetCategories()
{
var cacheCats = GetFromCache();
return cacheCats.Keys.ToList();
}
public List<PostListModel> GetPostsByCategory(string category)
{
var pages = GetFromCache()[category];
return GetPosts(pages.ToArray());
}
public BlogPostViewModel? GetPost(string postName)
{
try
{
var path = System.IO.Path.Combine(Path, postName + ".md");
var page = GetPage(path, true);
return new BlogPostViewModel
{
Categories = page.categories, WordCount = WordCount(page.restOfTheLines), Content = page.processed,
PublishedDate = page.publishDate, Slug = page.slug, Title = page.title
};
}
catch (Exception e)
{
_logger.LogError(e, "Error getting post {PostName}", postName);
return null;
}
}
private int WordCount(string text)
{
return WordCoountRegex.Matches(text).Count;
}
private string GetSlug(string fileName)
{
var slug = System.IO.Path.GetFileNameWithoutExtension(fileName);
return slug.ToLowerInvariant();
}
private static string[] GetCategories(string markdownText)
{
var matches = CategoryRegex.Matches(markdownText);
var categories = matches
.SelectMany(match => match.Groups.Cast<Group>()
.Skip(1) // Skip the entire match group
.Where(group => group.Success) // Ensure the group matched
.Select(group => group.Value.Trim()))
.ToArray();
return categories;
}
public (string title, string slug, DateTime publishDate, string processed, string[] categories, string
restOfTheLines) GetPage(string page, bool html)
{
var fileInfo = new FileInfo(page);
// Ensure the file exists
if (!fileInfo.Exists) throw new FileNotFoundException("The specified file does not exist.", page);
// Read all lines from the file
var lines = File.ReadAllLines(page);
// Get the title from the first line
var title = lines.Length > 0 ? Markdown.ToPlainText(lines[0].Trim()) : string.Empty;
// Concatenate the rest of the lines with newline characters
var restOfTheLines = string.Join(Environment.NewLine, lines.Skip(1));
// Extract categories from the text
var categories = GetCategories(restOfTheLines);
var publishedDate = fileInfo.CreationTime;
var publishDate = DateRegex.Match(restOfTheLines).Groups[1].Value;
if (!string.IsNullOrWhiteSpace(publishDate))
publishedDate = DateTime.ParseExact(publishDate, "yyyy-MM-ddTHH:mm", CultureInfo.InvariantCulture);
// Remove category tags from the text
restOfTheLines = CategoryRegex.Replace(restOfTheLines, "");
restOfTheLines = DateRegex.Replace(restOfTheLines, "");
// Process the rest of the lines as either HTML or plain text
var processed =
html ? Markdown.ToHtml(restOfTheLines, pipeline) : Markdown.ToPlainText(restOfTheLines, pipeline);
// Generate the slug from the page filename
var slug = GetSlug(page);
// Return the parsed and processed content
return (title, slug, publishedDate, processed, categories, restOfTheLines);
}
public List<PostListModel> GetPosts(string[] pages)
{
List<PostListModel> pageModels = new();
foreach (var page in pages)
{
var pageInfo = GetPage(page, false);
var summary = Markdown.ToPlainText(pageInfo.restOfTheLines).Substring(0, 100) + "...";
pageModels.Add(new PostListModel
{
Categories = pageInfo.categories, Title = pageInfo.title,
Slug = pageInfo.slug, WordCount = WordCount(pageInfo.restOfTheLines),
PublishedDate = pageInfo.publishDate, Summary = summary
});
}
pageModels = pageModels.OrderByDescending(x => x.PublishedDate).ToList();
return pageModels;
}
public List<PostListModel> GetPostsForFiles()
{
var pages = Directory.GetFiles("Markdown", "*.md");
return GetPosts(pages);
}
}
</details>
Όπως μπορείτε να δείτε αυτό έχει μερικά στοιχεία:
### Επεξεργασία αρχείων
Ο κώδικας για την επεξεργασία των αρχείων markdown σε HTML είναι αρκετά απλός, χρησιμοποιώ τη βιβλιοθήκη Markdig για να μετατρέψει το markdown σε HTML και στη συνέχεια χρησιμοποιώ μερικές κανονικές εκφράσεις για να αποσπάσει τις κατηγορίες και τη δημοσιευμένη ημερομηνία από το αρχείο markdown.
Η μέθοδος GetPage χρησιμοποιείται για την εξαγωγή του περιεχομένου του αρχείου markdown, έχει μερικά βήματα:
1. Απόσπασμα του τίτλου
Με τη σύμβαση χρησιμοποιώ την πρώτη γραμμή του αρχείου markdown ως τον τίτλο της θέσης. Οπότε μπορώ απλά να κάνω:
```csharp
var lines = File.ReadAllLines(page);
// Get the title from the first line
var title = lines.Length > 0 ? Markdown.ToPlainText(lines[0].Trim()) : string.Empty;
Καθώς ο τίτλος είναι προκαθορισμένος με το "#" χρησιμοποιώ τη μέθοδο Markdown.ToPlainText για να αφαιρέσω το "#" από τον τίτλο.
// Concatenate the rest of the lines with newline characters
var restOfTheLines = string.Join(Environment.NewLine, lines.Skip(1));
// Extract categories from the text
var categories = GetCategories(restOfTheLines);
// Remove category tags from the text
restOfTheLines = CategoryRegex.Replace(restOfTheLines, "");
Η μέθοδος GetCategories χρησιμοποιεί μια κανονική έκφραση για να αποσπάσει τις κατηγορίες από το αρχείο markdown.
private static readonly Regex CategoryRegex = new(@"<!--\s*category\s*--\s*([^,]+?)\s*(?:,\s*([^,]+?)\s*)?-->",
RegexOptions.Compiled | RegexOptions.Singleline);
private static string[] GetCategories(string markdownText)
{
var matches = CategoryRegex.Matches(markdownText);
var categories = matches
.SelectMany(match => match.Groups.Cast<Group>()
.Skip(1) // Skip the entire match group
.Where(group => group.Success) // Ensure the group matched
.Select(group => group.Value.Trim()))
.ToArray();
return categories;
}
private static readonly Regex DateRegex = new(
@"<datetime class=""hidden"">(\d{4}-\d{2}-\d{2}T\d{2}:\d{2})</datetime>",
RegexOptions.Compiled | RegexOptions.IgnoreCase | RegexOptions.NonBacktracking);
var publishedDate = fileInfo.CreationTime;
var publishDate = DateRegex.Match(restOfTheLines).Groups[1].Value;
if (!string.IsNullOrWhiteSpace(publishDate))
publishedDate = DateTime.ParseExact(publishDate, "yyyy-MM-ddTHH:mm", CultureInfo.InvariantCulture);
restOfTheLines = DateRegex.Replace(restOfTheLines, "");
pipeline = new MarkdownPipelineBuilder().UseAdvancedExtensions().Use<ImgExtension>().Build();
var processed =
html ? Markdown.ToHtml(restOfTheLines, pipeline) : Markdown.ToPlainText(restOfTheLines, pipeline);
Φέρε το "χαστούκι" Αυτό είναι απλά το όνομα αρχείου χωρίς την επέκταση:
private string GetSlug(string fileName)
{
var slug = System.IO.Path.GetFileNameWithoutExtension(fileName);
return slug.ToLowerInvariant();
}
Επιστροφή του περιεχομένου Τώρα έχουμε περιεχόμενο σελίδας που μπορούμε να εμφανίσουμε για το blog!
// Ensure the file exists
if (!fileInfo.Exists) throw new FileNotFoundException("The specified file does not exist.", page);
// Read all lines from the file
var lines = File.ReadAllLines(page);
// Get the title from the first line
var title = lines.Length > 0 ? Markdown.ToPlainText(lines[0].Trim()) : string.Empty;
// Concatenate the rest of the lines with newline characters
var restOfTheLines = string.Join(Environment.NewLine, lines.Skip(1));
// Extract categories from the text
var categories = GetCategories(restOfTheLines);
var publishedDate = fileInfo.CreationTime;
var publishDate = DateRegex.Match(restOfTheLines).Groups[1].Value;
if (!string.IsNullOrWhiteSpace(publishDate))
publishedDate = DateTime.ParseExact(publishDate, "yyyy-MM-ddTHH:mm", CultureInfo.InvariantCulture);
// Remove category tags from the text
restOfTheLines = CategoryRegex.Replace(restOfTheLines, "");
restOfTheLines = DateRegex.Replace(restOfTheLines, "");
// Process the rest of the lines as either HTML or plain text
var processed =
html ? Markdown.ToHtml(restOfTheLines, pipeline) : Markdown.ToPlainText(restOfTheLines, pipeline);
// Generate the slug from the page filename
var slug = GetSlug(page);
// Return the parsed and processed content
return (title, slug, publishedDate, processed, categories, restOfTheLines);
}
</details>
Ο παρακάτω κώδικας δείχνει πώς δημιουργώ τη λίστα των αναρτήσεων blog, χρησιμοποιεί το `GetPage(page, false)` μέθοδος εξαγωγής του τίτλου, των κατηγοριών, της δημοσιευμένης ημερομηνίας και του μεταποιημένου περιεχομένου.
```csharp
public List<PostListModel> GetPosts(string[] pages)
{
List<PostListModel> pageModels = new();
foreach (var page in pages)
{
var pageInfo = GetPage(page, false);
var summary = Markdown.ToPlainText(pageInfo.restOfTheLines).Substring(0, 100) + "...";
pageModels.Add(new PostListModel
{
Categories = pageInfo.categories, Title = pageInfo.title,
Slug = pageInfo.slug, WordCount = WordCount(pageInfo.restOfTheLines),
PublishedDate = pageInfo.publishDate, Summary = summary
});
}
pageModels = pageModels.OrderByDescending(x => x.PublishedDate).ToList();
return pageModels;
}
public List<PostListModel> GetPostsForFiles()
{
var pages = Directory.GetFiles("Markdown", "*.md");
return GetPosts(pages);
}
