This is a viewer only at the moment see the article on how this works.
To update the preview hit Ctrl-Alt-R (or ⌘-Alt-R on Mac) or Enter to refresh. The Save icon lets you save the markdown file to disk
This is a preview from the server running through my markdig pipeline
Markdown ist eine leichte Markup-Sprache, die Sie verwenden können, um Formatierungselemente zu Klartexttextdokumenten hinzuzufügen. Markdown wurde 2004 von John Gruber gegründet und ist heute eine der beliebtesten Markup-Sprachen der Welt.
Auf dieser Seite benutze ich einen super einfachen Ansatz zum Bloggen, nachdem ich versucht und versäumt habe, einen Blog in der Vergangenheit zu pflegen, wollte ich es so einfach wie möglich machen, Beiträge zu schreiben und zu veröffentlichen. Ich benutze Markdown, um meine Beiträge zu schreiben und diese Website hat einen einzigen Dienst mit Markdig zum Konvertieren des Markdowns in HTML.
In einem Wort Einfachheit. Dies wird nicht eine super hohe Traffic-Site sein, ich benutze ASP.NET OutPutCache, um die Seiten zu verbergen und ich werde es nicht so oft aktualisieren. Ich wollte die Website so einfach wie möglich zu halten und nicht über den Overhead eines statischen Seitengenerators sowohl in Bezug auf den Build-Prozess und die Komplexität der Website kümmern.
Zur Klärung; statische Standortgeneratoren wie Hugo / Jekyll etc...kann eine gute Lösung für viele Websites sein, aber für diese wollte ich es so einfach halten für mich ............................................................................................................................................................................................................................................................... Ich bin ein 25-jähriger ASP.NET-Veteran, also verstehen Sie es innen und außen. Diese Website-Design fügt Komplexität; Ich habe Ansichten, Dienste, Controller und eine große Menge von manuellen HTML & CSS, aber ich fühle mich damit wohl.
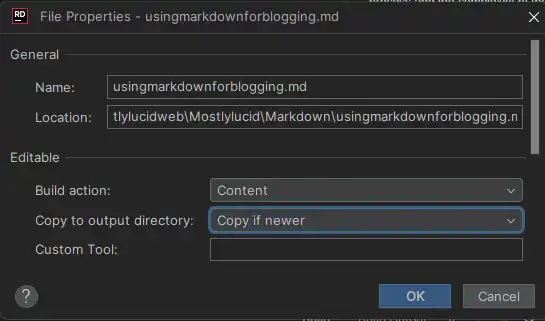
Ich lege einfach eine neue.md-Datei in den Markdown-Ordner und die Website nimmt sie auf und rendert sie (wenn ich mich daran erinnere, sie als Inhalt zu verwenden, stellt dies sicher, dass sie in den Ausgabedateien verfügbar ist! )
Wenn ich dann die Seite zu GitHub einchecke, läuft die Aktion und die Seite wird aktualisiert. Einfach!
Da ich gerade das Bild hier hinzugefügt habe, werde ich Ihnen zeigen, wie ich es gemacht habe. Ich habe das Bild einfach zum Ordner wwwroot/articleimages hinzugefügt und in der Markdown-Datei wie folgt referenziert:

Ich füge dann eine Erweiterung zu meiner Markdig Pipeline hinzu, die diese auf die korrekte URL umschreibt (alles über Einfachheit). Siehe hier für den Quellcode für die Erweiterung.
using Markdig;
using Markdig.Renderers;
using Markdig.Syntax;
using Markdig.Syntax.Inlines;
namespace Mostlylucid.MarkDigExtensions;
public class ImgExtension : IMarkdownExtension
{
public void Setup(MarkdownPipelineBuilder pipeline)
{
pipeline.DocumentProcessed += ChangeImgPath;
}
public void Setup(MarkdownPipeline pipeline, IMarkdownRenderer renderer)
{
}
public void ChangeImgPath(MarkdownDocument document)
{
foreach (var link in document.Descendants<LinkInline>())
if (link.IsImage)
link.Url = "/articleimages/" + link.Url;
}
}
Der BlogService ist ein einfacher Dienst, der die Markdown-Dateien aus dem Markdown-Ordner liest und mit Markdig in HTML konvertiert.
Die vollständige Quelle dafür ist unten und Hierher.
using System.Globalization; using System.Text.RegularExpressions; using Markdig; using Microsoft.Extensions.Caching.Memory; using Mostlylucid.MarkDigExtensions; using Mostlylucid.Models.Blog;
namespace Mostlylucid.Services;
public class BlogService { private const string Path = "Markdown"; private const string CacheKey = "Categories";
private static readonly Regex DateRegex = new(
@"<datetime class=""hidden"">(\d{4}-\d{2}-\d{2}T\d{2}:\d{2})</datetime>",
RegexOptions.Compiled | RegexOptions.IgnoreCase | RegexOptions.NonBacktracking);
private static readonly Regex WordCoountRegex = new(@"\b\w+\b",
RegexOptions.Compiled | RegexOptions.Multiline | RegexOptions.IgnoreCase | RegexOptions.NonBacktracking);
private static readonly Regex CategoryRegex = new(@"<!--\s*category\s*--\s*([^,]+?)\s*(?:,\s*([^,]+?)\s*)?-->",
RegexOptions.Compiled | RegexOptions.Singleline);
private readonly ILogger<BlogService> _logger;
private readonly IMemoryCache _memoryCache;
private readonly MarkdownPipeline pipeline;
public BlogService(IMemoryCache memoryCache, ILogger<BlogService> logger)
{
_logger = logger;
_memoryCache = memoryCache;
pipeline = new MarkdownPipelineBuilder().UseAdvancedExtensions().Use<ImgExtension>().Build();
ListCategories();
}
private Dictionary<string, List<string>> GetFromCache()
{
return _memoryCache.Get<Dictionary<string, List<string>>>(CacheKey) ?? new Dictionary<string, List<string>>();
}
private void SetCache(Dictionary<string, List<string>> categories)
{
_memoryCache.Set(CacheKey, categories, new MemoryCacheEntryOptions
{
AbsoluteExpirationRelativeToNow = TimeSpan.FromHours(12)
});
}
private void ListCategories()
{
var cacheCats = GetFromCache();
var pages = Directory.GetFiles("Markdown", "*.md");
var count = 0;
foreach (var page in pages)
{
var pageAlreadyAdded = cacheCats.Values.Any(x => x.Contains(page));
if (pageAlreadyAdded) continue;
var text = File.ReadAllText(page);
var categories = GetCategories(text);
if (!categories.Any()) continue;
count++;
foreach (var category in categories)
if (cacheCats.TryGetValue(category, out var pagesList))
{
pagesList.Add(page);
cacheCats[category] = pagesList;
_logger.LogInformation("Added category {Category} for {Page}", category, page);
}
else
{
cacheCats.Add(category, new List<string> { page });
_logger.LogInformation("Created category {Category} for {Page}", category, page);
}
}
if (count > 0) SetCache(cacheCats);
}
public List<string> GetCategories()
{
var cacheCats = GetFromCache();
return cacheCats.Keys.ToList();
}
public List<PostListModel> GetPostsByCategory(string category)
{
var pages = GetFromCache()[category];
return GetPosts(pages.ToArray());
}
public BlogPostViewModel? GetPost(string postName)
{
try
{
var path = System.IO.Path.Combine(Path, postName + ".md");
var page = GetPage(path, true);
return new BlogPostViewModel
{
Categories = page.categories, WordCount = WordCount(page.restOfTheLines), Content = page.processed,
PublishedDate = page.publishDate, Slug = page.slug, Title = page.title
};
}
catch (Exception e)
{
_logger.LogError(e, "Error getting post {PostName}", postName);
return null;
}
}
private int WordCount(string text)
{
return WordCoountRegex.Matches(text).Count;
}
private string GetSlug(string fileName)
{
var slug = System.IO.Path.GetFileNameWithoutExtension(fileName);
return slug.ToLowerInvariant();
}
private static string[] GetCategories(string markdownText)
{
var matches = CategoryRegex.Matches(markdownText);
var categories = matches
.SelectMany(match => match.Groups.Cast<Group>()
.Skip(1) // Skip the entire match group
.Where(group => group.Success) // Ensure the group matched
.Select(group => group.Value.Trim()))
.ToArray();
return categories;
}
public (string title, string slug, DateTime publishDate, string processed, string[] categories, string
restOfTheLines) GetPage(string page, bool html)
{
var fileInfo = new FileInfo(page);
// Ensure the file exists
if (!fileInfo.Exists) throw new FileNotFoundException("The specified file does not exist.", page);
// Read all lines from the file
var lines = File.ReadAllLines(page);
// Get the title from the first line
var title = lines.Length > 0 ? Markdown.ToPlainText(lines[0].Trim()) : string.Empty;
// Concatenate the rest of the lines with newline characters
var restOfTheLines = string.Join(Environment.NewLine, lines.Skip(1));
// Extract categories from the text
var categories = GetCategories(restOfTheLines);
var publishedDate = fileInfo.CreationTime;
var publishDate = DateRegex.Match(restOfTheLines).Groups[1].Value;
if (!string.IsNullOrWhiteSpace(publishDate))
publishedDate = DateTime.ParseExact(publishDate, "yyyy-MM-ddTHH:mm", CultureInfo.InvariantCulture);
// Remove category tags from the text
restOfTheLines = CategoryRegex.Replace(restOfTheLines, "");
restOfTheLines = DateRegex.Replace(restOfTheLines, "");
// Process the rest of the lines as either HTML or plain text
var processed =
html ? Markdown.ToHtml(restOfTheLines, pipeline) : Markdown.ToPlainText(restOfTheLines, pipeline);
// Generate the slug from the page filename
var slug = GetSlug(page);
// Return the parsed and processed content
return (title, slug, publishedDate, processed, categories, restOfTheLines);
}
public List<PostListModel> GetPosts(string[] pages)
{
List<PostListModel> pageModels = new();
foreach (var page in pages)
{
var pageInfo = GetPage(page, false);
var summary = Markdown.ToPlainText(pageInfo.restOfTheLines).Substring(0, 100) + "...";
pageModels.Add(new PostListModel
{
Categories = pageInfo.categories, Title = pageInfo.title,
Slug = pageInfo.slug, WordCount = WordCount(pageInfo.restOfTheLines),
PublishedDate = pageInfo.publishDate, Summary = summary
});
}
pageModels = pageModels.OrderByDescending(x => x.PublishedDate).ToList();
return pageModels;
}
public List<PostListModel> GetPostsForFiles()
{
var pages = Directory.GetFiles("Markdown", "*.md");
return GetPosts(pages);
}
}
</details>
Wie Sie sehen können, hat dies ein paar Elemente:
### Verarbeitung von Dateien
Der Code, um die Markdown-Dateien in HTML zu verarbeiten, ist ziemlich einfach, ich benutze die Markdig-Bibliothek, um den Markdown in HTML zu konvertieren und dann benutze ich ein paar reguläre Ausdrücke, um die Kategorien und das veröffentlichte Datum aus der Markdown-Datei zu extrahieren.
Die GetPage-Methode wird verwendet, um den Inhalt der Markdown-Datei zu extrahieren, es hat ein paar Schritte:
1. Den Titel extrahieren
Durch Konvention verwende ich die erste Zeile der Markdown-Datei als Titel des Posts. So kann ich es einfach tun:
```csharp
var lines = File.ReadAllLines(page);
// Get the title from the first line
var title = lines.Length > 0 ? Markdown.ToPlainText(lines[0].Trim()) : string.Empty;
Da der Titel mit "#" voreingestellt ist, benutze ich die Markdown.ToPlainText Methode, um das "#" vom Titel zu entfernen.
// Concatenate the rest of the lines with newline characters
var restOfTheLines = string.Join(Environment.NewLine, lines.Skip(1));
// Extract categories from the text
var categories = GetCategories(restOfTheLines);
// Remove category tags from the text
restOfTheLines = CategoryRegex.Replace(restOfTheLines, "");
Die GetCategories-Methode verwendet einen regulären Ausdruck, um die Kategorien aus der Markdown-Datei zu extrahieren.
private static readonly Regex CategoryRegex = new(@"<!--\s*category\s*--\s*([^,]+?)\s*(?:,\s*([^,]+?)\s*)?-->",
RegexOptions.Compiled | RegexOptions.Singleline);
private static string[] GetCategories(string markdownText)
{
var matches = CategoryRegex.Matches(markdownText);
var categories = matches
.SelectMany(match => match.Groups.Cast<Group>()
.Skip(1) // Skip the entire match group
.Where(group => group.Success) // Ensure the group matched
.Select(group => group.Value.Trim()))
.ToArray();
return categories;
}
private static readonly Regex DateRegex = new(
@"<datetime class=""hidden"">(\d{4}-\d{2}-\d{2}T\d{2}:\d{2})</datetime>",
RegexOptions.Compiled | RegexOptions.IgnoreCase | RegexOptions.NonBacktracking);
var publishedDate = fileInfo.CreationTime;
var publishDate = DateRegex.Match(restOfTheLines).Groups[1].Value;
if (!string.IsNullOrWhiteSpace(publishDate))
publishedDate = DateTime.ParseExact(publishDate, "yyyy-MM-ddTHH:mm", CultureInfo.InvariantCulture);
restOfTheLines = DateRegex.Replace(restOfTheLines, "");
pipeline = new MarkdownPipelineBuilder().UseAdvancedExtensions().Use<ImgExtension>().Build();
var processed =
html ? Markdown.ToHtml(restOfTheLines, pipeline) : Markdown.ToPlainText(restOfTheLines, pipeline);
Holen Sie den 'Schlupf' Dies ist einfach der Dateiname ohne die Erweiterung:
private string GetSlug(string fileName)
{
var slug = System.IO.Path.GetFileNameWithoutExtension(fileName);
return slug.ToLowerInvariant();
}
Inhalt zurückgeben Jetzt haben wir Seiteninhalte, die wir für den Blog anzeigen können!
// Ensure the file exists
if (!fileInfo.Exists) throw new FileNotFoundException("The specified file does not exist.", page);
// Read all lines from the file
var lines = File.ReadAllLines(page);
// Get the title from the first line
var title = lines.Length > 0 ? Markdown.ToPlainText(lines[0].Trim()) : string.Empty;
// Concatenate the rest of the lines with newline characters
var restOfTheLines = string.Join(Environment.NewLine, lines.Skip(1));
// Extract categories from the text
var categories = GetCategories(restOfTheLines);
var publishedDate = fileInfo.CreationTime;
var publishDate = DateRegex.Match(restOfTheLines).Groups[1].Value;
if (!string.IsNullOrWhiteSpace(publishDate))
publishedDate = DateTime.ParseExact(publishDate, "yyyy-MM-ddTHH:mm", CultureInfo.InvariantCulture);
// Remove category tags from the text
restOfTheLines = CategoryRegex.Replace(restOfTheLines, "");
restOfTheLines = DateRegex.Replace(restOfTheLines, "");
// Process the rest of the lines as either HTML or plain text
var processed =
html ? Markdown.ToHtml(restOfTheLines, pipeline) : Markdown.ToPlainText(restOfTheLines, pipeline);
// Generate the slug from the page filename
var slug = GetSlug(page);
// Return the parsed and processed content
return (title, slug, publishedDate, processed, categories, restOfTheLines);
}
</details>
Der Code unten zeigt, wie ich die Liste der Blog-Posts zu generieren, es verwendet die `GetPage(page, false)` Methode zum Extrahieren des Titels, der Kategorien, des veröffentlichten Datums und des verarbeiteten Inhalts.
```csharp
public List<PostListModel> GetPosts(string[] pages)
{
List<PostListModel> pageModels = new();
foreach (var page in pages)
{
var pageInfo = GetPage(page, false);
var summary = Markdown.ToPlainText(pageInfo.restOfTheLines).Substring(0, 100) + "...";
pageModels.Add(new PostListModel
{
Categories = pageInfo.categories, Title = pageInfo.title,
Slug = pageInfo.slug, WordCount = WordCount(pageInfo.restOfTheLines),
PublishedDate = pageInfo.publishDate, Summary = summary
});
}
pageModels = pageModels.OrderByDescending(x => x.PublishedDate).ToList();
return pageModels;
}
public List<PostListModel> GetPostsForFiles()
{
var pages = Directory.GetFiles("Markdown", "*.md");
return GetPosts(pages);
}
